 היום הווב מאפשר לקשור בין מסמכים קשורים. באופן דומה הווב יכול לאפשר לקשור בין נתונים קשורים. וזוהי מטרתו של הווב הסמנטי אשר מורכב למעשה מנתונים מקושרים . מטרת הנתונים המקושרים היא לאפשר שיתוף בין נתונים מובנים בווב באותה קלות שניתן היום לשתף מסמכים. הנתונים המובנים יכולים לכלול מידע בנושאים שונים: מדע, בריאות, חדשות, מידע ממשלתי ועוד
היום הווב מאפשר לקשור בין מסמכים קשורים. באופן דומה הווב יכול לאפשר לקשור בין נתונים קשורים. וזוהי מטרתו של הווב הסמנטי אשר מורכב למעשה מנתונים מקושרים . מטרת הנתונים המקושרים היא לאפשר שיתוף בין נתונים מובנים בווב באותה קלות שניתן היום לשתף מסמכים. הנתונים המובנים יכולים לכלול מידע בנושאים שונים: מדע, בריאות, חדשות, מידע ממשלתי ועוד
ומה לגבי מידע ספרני? ספריות מייצרות היום מידע דיגיטלי כדי לתאר מקורות מידע או כדי לסייע באחזורו. מידע זה כולל רשומות ביבליוגרפיות , זהויות, וסכימות של מושגים.
מידע זה נמצא היום במאגרי מידע שיש להם לרוב מנשק וובי אבל הם לא משולבים באופן עמוק עם מקורות אחרים בווב.
המצב היום הוא שהסטנדרטים של הספרייה כגון MARC או הפרוטוקול לאחזור מידע – Z39.50 מתוכננים רק לקהילה הספרנית, ולקהילה הספרנית ולקהילת הווב הסמנטי טרמינולוגיה שונה לאותם מושגים של מידע על . במצב זה, בעתיד בסביבה של נתונים מקושרים, בהם הנתונים מבוטאים על ידי סטנדרטים שונים כגון RDF שמגדיר יחסים בין דברים ו- URI להגדרת כתובות אינטרנט, קשה יהיה לקשר בין מידע ספרני ומקורות אחרים בווב. .
המטרה שהציבה לה הקבוצה Library Linked Data Incubator Group שפעלה במסגרת קונסורציום הרשת הכלל עולמית W3C בתקופה מאי 2010 ועד אוגוסט 2011 , היא לעזור להגדיל את האינטראופרביליות של המידע הדיגיטלי שמיוצר בספריות לצורך תיאור מקורות מידע או שעוזר לאחזורן, על ידי קיבוץ אנשים מקהילת הספרייה ומחוצה לה, שמעורבים בפעילות הווב הסמנטי ומתמקדים בנתונים המקושרים, לצורך הגדרת צעדים לקראת שיתוף פעולה בעתיד..
הדוח הסופי של הקבוצה מאוקטובר 2011 בדק כיצד ניתן להשתמש בסטנדרטים של הווב הסמנטי ובעקרונות של הנתונים המקושרים כדי להגדיל את הנראות של המידע שמייצרת ומשמרת הספרייה כגון רשומות ביבליוגרפיות וזהויות ולאפשר שימוש מחודש במידע זה בווב מחוץ לספרייה המקורית .
הדוח ניתח את התועלת בנתונים המקושרים לחוקרים, לסטודנטים ,לארגונים, לספרנים למפתחים ולספקים, כלל דיון בנושאים שקשורים לנתונים של הספרייה המסורתית, יזמות של ספריות בכל הקשור לנתונים מקושרים, היבטים משפטיים שקשורים לזכויות על המידע שמייצרת הספרייה , והמלצות לצעדים הבאים. הדוח כלל גם סיכום של תוצאות סקר על הטכנולוגיות העכשוויות של הנתונים המקושרים, ומקורות שקשורים לנתונים מקושרים וספריות, שזמינים היום.
ההמלצות בדוח דנו במספר נושאים ובראשם: כיצד להגדיל את האינטראופרביליות של המידע המיוצר בספריות ולהגדיל את השיתוף של הספרייה בתקינה של הווב הסמנטי, וכיצד לפתח תקנים של ספרייה שתואמים את הנתונים המקושרים. – ההמלצות התייחסו למנהלי הספריות, לגופים האחראים על התקנים, למעצבי מערכות , ולספרנים וארכיונאים.
לדוח המלא
תודה לאייל סלע , מנהל פרוייקטים באיגוד האינטרנט הישראלי ומשרד ה- W3C הישראלי על ההפניה לדו"ח זה

 היום הוויקיפדיה כוללת עובדות וקישורים למאמרים אחרים שלא מובנים בקלות על ידי מחשבים. דוגמאות למידע עובדתי זה הם נתונים על אוכלוסייה של ארץ מסוימת או מקום הולדתה של אישיות מסוימת.
היום הוויקיפדיה כוללת עובדות וקישורים למאמרים אחרים שלא מובנים בקלות על ידי מחשבים. דוגמאות למידע עובדתי זה הם נתונים על אוכלוסייה של ארץ מסוימת או מקום הולדתה של אישיות מסוימת. היום הווב מאפשר לקשור בין מסמכים קשורים. באופן דומה הווב יכול לאפשר לקשור בין נתונים קשורים.
היום הווב מאפשר לקשור בין מסמכים קשורים. באופן דומה הווב יכול לאפשר לקשור בין נתונים קשורים.  ענן תגיות שמשקף את נושאי ההרצאות בשנת 2011 לעומת הנושאים בכנס הראשון ב- 2001 יכול לשקף ולשפוך מעט אור על ההתפתחויות במשך השנים בנושא. השנה המונח DATA מופיע בגדול, המונח ONTOLOGY שומר על מקומו בשני הכנסים לעומת זאת המונח WEB שהופיע ב- 2001 כמעט נעלם השנה והמונח query שלא הופיע ב- 2001 כן מופיע השנה.
ענן תגיות שמשקף את נושאי ההרצאות בשנת 2011 לעומת הנושאים בכנס הראשון ב- 2001 יכול לשקף ולשפוך מעט אור על ההתפתחויות במשך השנים בנושא. השנה המונח DATA מופיע בגדול, המונח ONTOLOGY שומר על מקומו בשני הכנסים לעומת זאת המונח WEB שהופיע ב- 2001 כמעט נעלם השנה והמונח query שלא הופיע ב- 2001 כן מופיע השנה. היא אפליקציה תואמת ווב וגם מגוון פלטפורמות ניידות : iPad, iPhone, BlackBerry PlayBook, Windows Phone, Android אשר מציגה למשתמש חדשות רלוונטיות לו על סמך פעילותו באתרים חברתיים. News360 עושה שימוש בטכנולוגיות סמנטיות וכרית מידע. היא מנתחת את פעילותו של המשתמש באתרים חברתיים כגון: Facebook, Twitter, Google Reader, Evernote במטרה לבחור חדשות רלוונטיות למשתמש מכול מקור שהוא.. ניתוח הפעילות של המשתמש באתרים החברתיים מתבצע כמובן בהרשאתו של המשתמש.
היא אפליקציה תואמת ווב וגם מגוון פלטפורמות ניידות : iPad, iPhone, BlackBerry PlayBook, Windows Phone, Android אשר מציגה למשתמש חדשות רלוונטיות לו על סמך פעילותו באתרים חברתיים. News360 עושה שימוש בטכנולוגיות סמנטיות וכרית מידע. היא מנתחת את פעילותו של המשתמש באתרים חברתיים כגון: Facebook, Twitter, Google Reader, Evernote במטרה לבחור חדשות רלוונטיות למשתמש מכול מקור שהוא.. ניתוח הפעילות של המשתמש באתרים החברתיים מתבצע כמובן בהרשאתו של המשתמש. I-Search
I-Search בפוסט קודם
בפוסט קודם הוא מנוע חיפוש רפואי למשתמש שפותח על יד חברת
הוא מנוע חיפוש רפואי למשתמש שפותח על יד חברת  ב- 2 ביוני 2011
ב- 2 ביוני 2011  BioPortal
BioPortal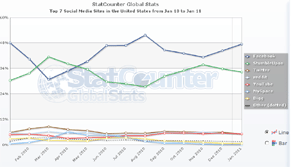 עם תחילתה של השנה החדשה מעניין מה היו המגמות ברשת האינטרנט בשנה החולפת ומה הן התחזיות לעתיד.
עם תחילתה של השנה החדשה מעניין מה היו המגמות ברשת האינטרנט בשנה החולפת ומה הן התחזיות לעתיד. 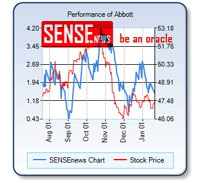 מחפשים טיפים בכל הקשור להשקעות במניות – רכישה ומכירה. יתכן שתוכלו בשלב זה להיעזר תמורת תשלום חודשי בשירות החדש
מחפשים טיפים בכל הקשור להשקעות במניות – רכישה ומכירה. יתכן שתוכלו בשלב זה להיעזר תמורת תשלום חודשי בשירות החדש  גיליון ראשון של
גיליון ראשון של  במאמר מעניין שהתפרסם בגיליון דצמבר 2010 של Scientific American
במאמר מעניין שהתפרסם בגיליון דצמבר 2010 של Scientific American Kngine הוא מנוע חיפוש סמנטי שמשתמש בטכנולוגיות מתקדמות כדי להבין את המשמעות של התכנים , לספק תשובות לשאלות המשתמש ולחפש קשרים בין סוגי מידע שונים שקשורים לשאילתה של המשתמש.
Kngine הוא מנוע חיפוש סמנטי שמשתמש בטכנולוגיות מתקדמות כדי להבין את המשמעות של התכנים , לספק תשובות לשאלות המשתמש ולחפש קשרים בין סוגי מידע שונים שקשורים לשאילתה של המשתמש.