
 ZANRAN הוא מנוע חיפוש ייעודי לנתונים סטטיסטיים. המנוע מחפש נתונים נומריים שמיוצגים בגרפים , בטבלאות ובתרשימים. מטרתו של המנוע היא לחלץ מידע נומרי מתוך קובצי PDF, Excel , קובצי html, PowerPoint ו- Word .
ZANRAN הוא מנוע חיפוש ייעודי לנתונים סטטיסטיים. המנוע מחפש נתונים נומריים שמיוצגים בגרפים , בטבלאות ובתרשימים. מטרתו של המנוע היא לחלץ מידע נומרי מתוך קובצי PDF, Excel , קובצי html, PowerPoint ו- Word .
מידע כזה קשה לאתר בחיפוש במנועי חיפוש כלליים רגילים שמתמקדים בעיקר בחיפוש טקסט .
ZANRAN מאתר מיליוני תמונות ומחליט לגבי כל אחת האם היא כוללת תכנים מספריים בצורת גרף , טבלה או תרשים.
האלגוריתם מבוסס על טכנולוגיה של ראיה ממוחשבת שבעזרתה מתקבלת ההחלטה האם התמונה היא נומרית והדיוק על פי מה שנכתב באתר הוא בסביבות 98% – כך שיתכן שיתקבלו בתוצאות החיפוש לעתים רחוקות גם תמונות לא נומריות.
במנשק התוצאות בצד כל אחת מתוצאות החיפוש יש אייקון של סוג הקובץ ממנו נלקחה התוצאה. העברת העכבר על האייקון מאפשרת תצוגה מקדימה של האובייקט – גרף טבלה או רישום. לחיצה על האייקון או על הכותר פותחת את הקובץ בו נמצאים הנתונים המספריים שמיוצגים על ידי רישומים, גרפים או טבלאות.
במעט החיפושים שערכתי באתר קיבלתי מספר רב של תוצאות והתוצאות שבדקתי היו רלוונטיות לחיפוש.
על פי מה שנכתב באתר – מיפוי המידע הסטטיסטי בווב מתאפשר הודות לפיתוח תוכנה בקוד פתוח ואחסון זול במחשוב עננים. מנוע החיפוש סורק חלקים גדולים ברשת אבל מפתחיו ישמחו על המלצות לאתרים טובים שאולי הוחמצו.
 ב- 2 ביוני 2011
ב- 2 ביוני 2011  מנועי החיפוש וגוגל בתוכם משתדלים להתאים את תוצאות החיפוש למשתמש.
מנועי החיפוש וגוגל בתוכם משתדלים להתאים את תוצאות החיפוש למשתמש.  Blogpulse
Blogpulse BioPortal
BioPortal Yometa הוא מנוע חיפוש-על שמחפש בשלושת מנועי החיפוש הגדולים: גוגל, בינג ויאהו ומציג את תוצאות החיפוש בצורה ויזואלית.
Yometa הוא מנוע חיפוש-על שמחפש בשלושת מנועי החיפוש הגדולים: גוגל, בינג ויאהו ומציג את תוצאות החיפוש בצורה ויזואלית. כאשר אנו רוצים להוסיף תמונה חינמית מהרשת לבלוג או לכול מידע אחר שאנו מפרסמים , חשוב מתוך האוסף ההולך וגדל של תמונות לבחור את התמונות שזמינות לנו חופשי במסגרת רישיון גמיש שמתיר שימוש, הפצה ושימוש חוזר בתמונה מבלי להפר זכויות יוצרים. רישיון creative commons מתיר זאת.
כאשר אנו רוצים להוסיף תמונה חינמית מהרשת לבלוג או לכול מידע אחר שאנו מפרסמים , חשוב מתוך האוסף ההולך וגדל של תמונות לבחור את התמונות שזמינות לנו חופשי במסגרת רישיון גמיש שמתיר שימוש, הפצה ושימוש חוזר בתמונה מבלי להפר זכויות יוצרים. רישיון creative commons מתיר זאת. מנועי חיפוש משתדלים להתאים את תוצאות החיפוש למשתמש – מחפש המידע. עד כה מנועי החיפוש לקחו בחשבון יחסים בין נתונים, כיום נראה שהם מוסיפים לתוצאות החיפוש גם יחסים בין אנשים – רובד חברתי לחיפוש.
מנועי חיפוש משתדלים להתאים את תוצאות החיפוש למשתמש – מחפש המידע. עד כה מנועי החיפוש לקחו בחשבון יחסים בין נתונים, כיום נראה שהם מוסיפים לתוצאות החיפוש גם יחסים בין אנשים – רובד חברתי לחיפוש. Greplin
Greplin עם הגידול במידע עדכני בזמן אמת ברשת נולד הצורך להתאים את מנועי החיפוש לסביבת המידע המשתנה.
עם הגידול במידע עדכני בזמן אמת ברשת נולד הצורך להתאים את מנועי החיפוש לסביבת המידע המשתנה.  היום – 26 בינואר, יד ושם וגוגל השיקו
היום – 26 בינואר, יד ושם וגוגל השיקו 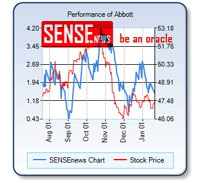 מחפשים טיפים בכל הקשור להשקעות במניות – רכישה ומכירה. יתכן שתוכלו בשלב זה להיעזר תמורת תשלום חודשי בשירות החדש
מחפשים טיפים בכל הקשור להשקעות במניות – רכישה ומכירה. יתכן שתוכלו בשלב זה להיעזר תמורת תשלום חודשי בשירות החדש  מנוע החיפוש BLekko
מנוע החיפוש BLekko לחוקרים ולכל המחפשים מידע במדעי החיים והרפואה – אם כתבתם לאחרונה מאמר ואינכם יודעים לאיזה כתב עת לשלוח אותו? מחפשים מאמרים רלוונטיים לנושא המאמר כדי לצטט אותם? אתם עורכים של כתבי עת שפיטים ומחפשים מבקרים למאמרים –
לחוקרים ולכל המחפשים מידע במדעי החיים והרפואה – אם כתבתם לאחרונה מאמר ואינכם יודעים לאיזה כתב עת לשלוח אותו? מחפשים מאמרים רלוונטיים לנושא המאמר כדי לצטט אותם? אתם עורכים של כתבי עת שפיטים ומחפשים מבקרים למאמרים –