
השבוע הושלם באוניברסיטת תל אביב פרויקט מחקרי רחב היקף לשחזור מרשם הפטנטים שפעל בארץ ישראל בתקופת המנדט הבריטי. פרויקט זה זמין לכל דורש באתר האינטרנט "מאגר הפטנטים המשוחזר של פלשתינה א"י המנדטורית". מסד הנתונים מאפשר לעיין באופן מקוון בכל הפטנטים שנרשמו על ידי הממשל הבריטי בארץ ישראל בין 1924 לקום המדינה ב-1948, ומצטרף לפרויקט שחזור סימני מסחר (trademarks) מאותה תקופה.
הפרויקט הובל ע"י פרופ' מיכאל בירנהק מהפקולטה למשפטים יחד עם צוות של עוזרי ועוזרות מחקר, שאיתרו כ-4,395 בקשות לרישום פטנטים ממקורות שונים כדוגמת רשות הפטנטים במשרד המשפטים ופרסומים ברשומות בארץ ומעבר לים. המידע שלוקט עבר דיגיטציה והעשרה ברמת ה-Metadata (שם המבקש, כתובת, סוכן פטנטים, תאריכים).
לאחר סיום עבודת הליקוט פנה פרופ' בירנהק לספרייה כדי שתסייע בידו להנגיש את מסד הנתונים לקהל הרחב. כך נוצר שיתוף פעולה פורה בין הספרייה למדעי החברה והספרייה המרכזית, שבמסגרתו הונגשו כלל בקשות הפטנטים כרשומות בקטלוג הספריות.
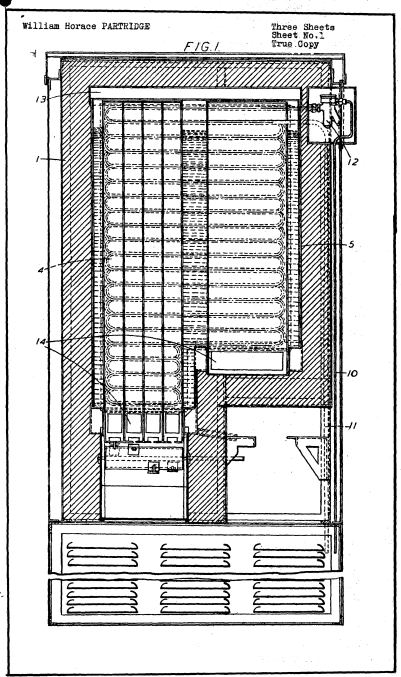
איור מתוך בקשת פטנט למניעת הצטברות קרח במנגנון הרכישה של מכונות לממכר אוטומטי של גלידה באמצעות מטבעות (Application 3579, 19.7.1945)
בהתאם לצרכי הפרויקט נוצר ממשק חיפוש נפרד וייעודי במערכת Primo VE תחת השם Mandat Palestine: Trademark and Patent Registries (1922-1948), אשר צורף לממשק של פרויקט סימני המסחר. ממשק זה מאפשר למשתמשים לגשת למסד הנתונים בנפרד ממסד הנתונים הכללי של הספריות. כך, לדוגמה, ניתן לחפש פטנטים הקשורים בשימור מיץ תפוזים מבלי שיכללו בתוצאות החיפוש גם ספרים או משאבים אלקטרוניים אחרים שעוסקים בנושא זה ואשר נמצאים ברשות הספרייה.
צוות המחקר איגד את שדות ה-Metadata שלוקטו עבור כל בקשת פטנט בתוך מבנה טבלאי. הבקשות הוטענו לעלמא על ידי צוותי הספריות, כאשר כל בקשה יוצגה כרשומה ביבליוגרפית נפרדת בממשק הייעודי. בשלב השני, לכל רשומה ביבליוגרפית הוצמדו קבצי בקשות הפטנט והוטענו לעלמא.
קבצי בקשות הפטנטים התקבלו מצוות המחקר בפורמט PDF שאינו מאפשר חיפוש בתוכן הבקשות. כדי לשפר את אפשרויות ההנגשה והחיפוש, צוות הספרייה הריץ אלגוריתם זיהוי תווים אופטי (OCR) על כלל הקבצים. אלגוריתם זה מאפשר להמיר מסמכים סרוקים למסמך תמליל ממוחשב ע"י זיהוי התווים המרכיבים את הטקסט. הטקסט שזוהה מהווה שכבה נוספת בתוך קבצי ה-PDF, כך שניתן לחפש ולהעתיק מכל בקשת פטנט. לאחר הרצת האלגוריתם על כלל הבקשות הופקו נתונים סטטיסטיים המעידים על דיוק של בין 87% ל-92% (פלטפורמת ה-OCR שנבחרה לצורך הפרויקט הינה של חברת ABBYY).
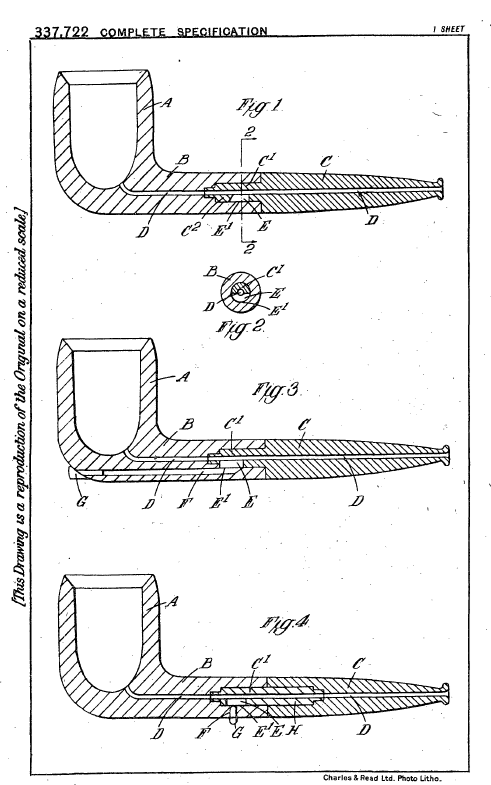
איור מתוך בקשת פטנט לשיפור בתא החימום של מקטרות טבק (Application 0180, 20.5.1931)
לאחר סיום תהליך זיהוי התווים על כלל בקשות הפטנט, הופקו, לראשונה במערכת הספריות, סיכומים שנוצרו בבינה מלאכותית עבור כל בקשה. בקצרה, פלט ה-OCR עבור כל בקשה נשלח דרך בקשת API למודל שפה גדול (LLM). מודל השפה, במקרה זה ג'מיני של גוגל, התבקש ליצור סיכום קצר של כל בקשה באמצעות ההנחיה (prompt) הבאה:
"This document is a historical patent application. You are tasked with summarizing it for the purpose of library cataloging. Please give me a summary of the following text up to 150 words. Do not include names of people or dates.”
לאחר מספר רב של בדיקות אוטומטיות וידניות שהעלו כי סיכומים אלו נאמנים למקור, סיכומי ה-AI הועלו לשדה Metadata ייעודי בכל בקשת פטנט. כך למעשה ניתן לחפש גם בתוך הטקסט של בקשות הפטנט, בשדות ה-Metadata ובסיכומי הבינה המלאכותית.
המאגר פתוח לעיון, למחקר, ולכל שימוש לא מסחרי. חוקרים וחוקרות מוזמנים לעיין ולחקור – יש במאגר פוטנציאל למחקרים מסוגים מגוונים, למשל מיקרו-היסטוריה על ממציאים או המצאות מסוימים, היסטוריה עסקית של תאגידים מסוימים או תעשיות מסוימות, מחקרים כלכליים וגיאו-פוליטיים, למשל על דפוסי הגירה מול נתוני הפטנטים וזהות המבקשים, מחקרים כלכליים על דיפוזיה של ידע, ומחקרים על השפעת המשפט על הנ"ל.
מוזמנים ומוזמנות להיכנס לממשק החיפוש הייעודי ולערוך חיפוש בפטנטים או בסימני מסחר, להגביל לפי מגיש הבקשה, שנים, וסננים נוספים.